個人系統 · Notion
Notion 個人資料庫起手式:打造第二大腦的四個核心資料庫
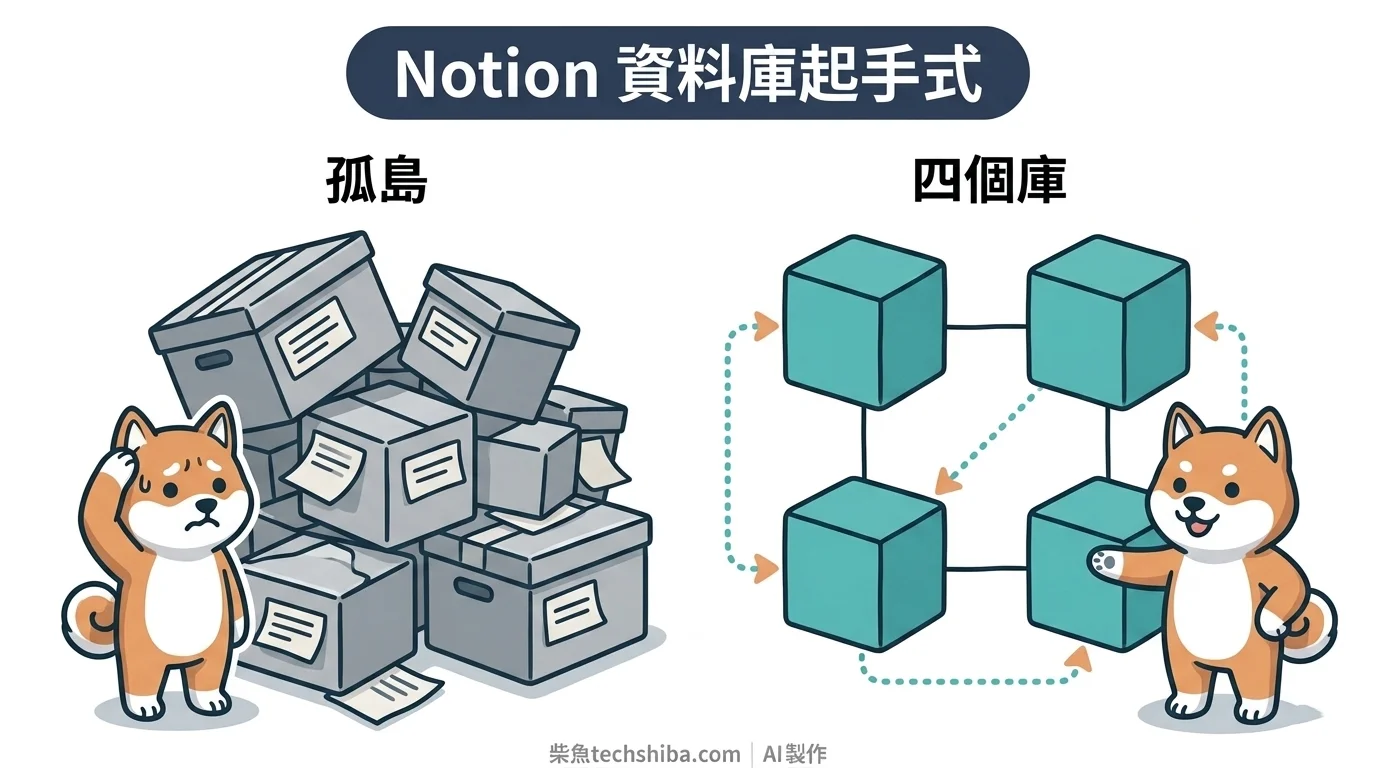
開十幾個 Notion 資料庫卻三個月就荒掉?問題不在模板,而在資料庫該對應「資訊流動的階段」而非主題。本文用《打造第二大腦》CODE 流程,教你只建四個核心資料庫+relation,並把 schema 設計成 AI 讀得懂,讓 AI 幫你自動分類、摘要、產出。
你有沒有發現,每次打開 Notion、準備新增一個 Notion 個人資料庫之前,腦袋裡冒出來的念頭,幾乎都是「我要記在哪裡?」記讀書筆記,開一個「書摘庫」;追劇,開一個「片單」;我有靈感,開一個「靈感庫」。庫的名字,全都對應主題。
我曾經深信這樣沒問題。最誇張的時候,我同時開了十幾個 inline 資料庫,抄了一堆很漂亮的模板,結果三個月後沒有一個還在更新。不是我懶,是那些庫對應的「主題」並沒有融入我的工作流,片段式的輸入未整理過的資訊,未來也不知道如何取用它。
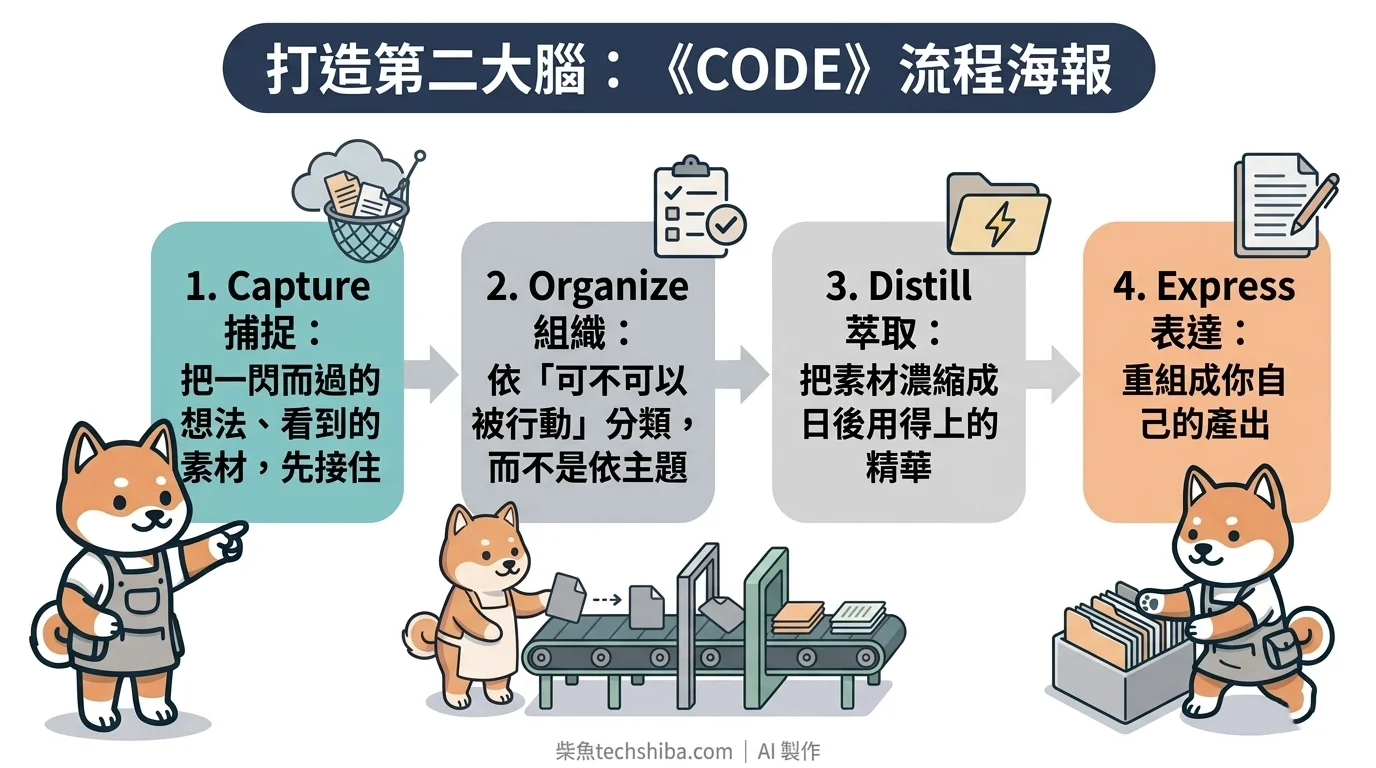
直到我讀完《打造第二大腦》(Building a Second Brain),才把這件事真正想通。作者 Tiago Forte 提出一套叫 CODE 的流程,描述任何一筆資訊在你腦袋外的生命週期:
- Capture 捕捉:把一閃而過的想法、看到的素材,先接住
- Organize 組織:依「可不可以被行動」分類,而不是依主題
- Distill 萃取:把素材濃縮成日後用得上的精華
- Express 表達:重組成你自己的產出
轉念就在這裡:你的資料庫不該對應「主題」,該對應「資訊在你工作流哪個階段」。 想通這件事之後,我決定花一次完整的功夫,系統性思考我的需求,並問自己三個問題:
- 這筆資訊從哪裡進來?(→ 捕捉)
- 進來之後,它要被執行、還是被參考?(→ 組織 vs 萃取)
- 它最後要變成什麼產出?(→ 表達)
於是我發現不是每個相關分類都放在各別的資料庫就好,而是依我的使用習慣思考該建幾個關鍵資料庫,不同分類以欄位區分,甚至不同用途時只需要設計好篩選機制及自動化,就能用最簡潔的資料庫架構收集資訊。
📌 這篇會有三大重點:
- 資料庫對應 CODE 流動階段如何設計。
- 4 個對的資料庫 + relation,勝過 50 個孤島資料庫。
- schema 要為 AI 設計,你才能「請 AI 幫你充實」
我的 Notion 個人資料庫:依《打造第二大腦》建的四個庫
我應用 CODE 的四個階段,設計了資料庫;其中「組織」階段是用專案+行動任務兩張表,靠 relation 綁在一起:
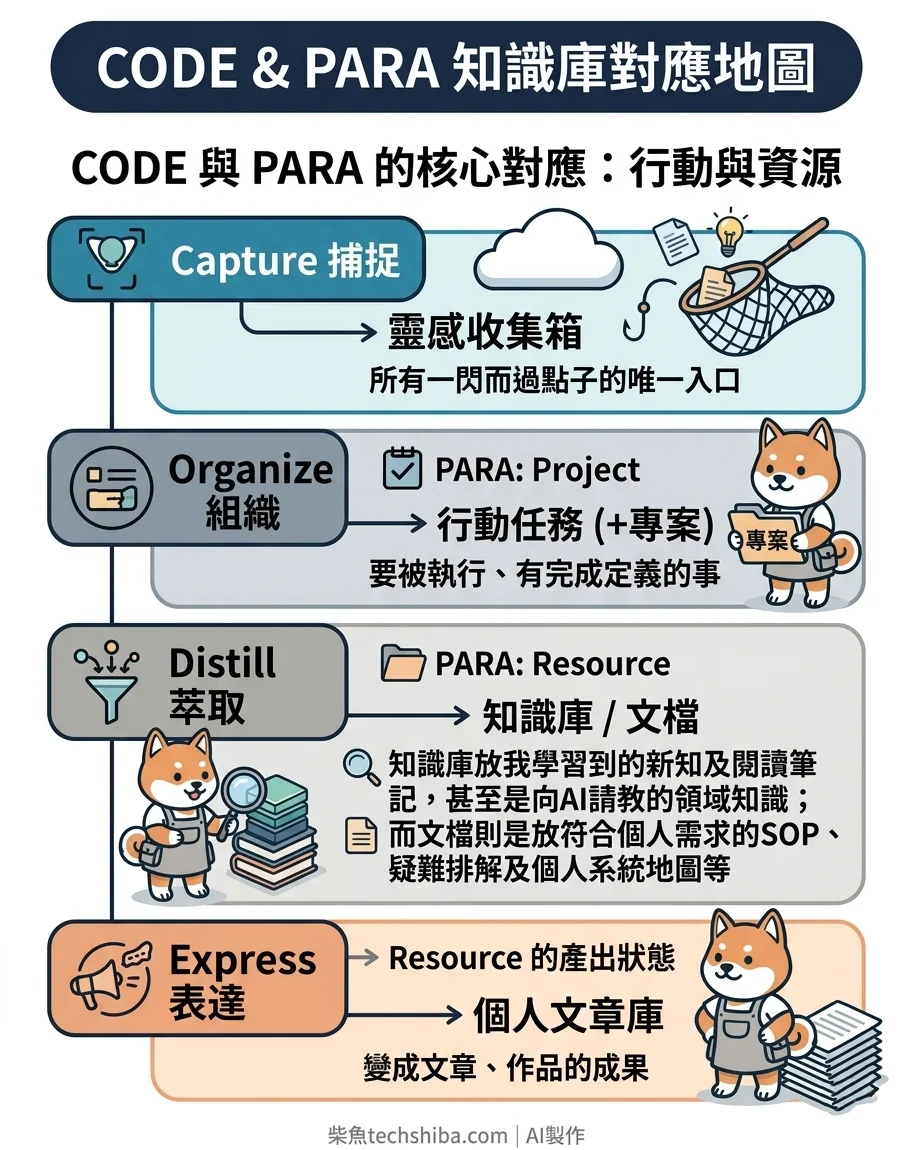
| CODE 階段 | PARA | 我建的庫 | 負責的事 |
|---|---|---|---|
| Capture 捕捉 | — | 靈感收集箱 | 所有一閃而過點子的唯一入口 |
| Organize 組織 | Project | 行動任務(+專案) | 要被執行、有完成定義的事 |
| Distill 萃取 | Resource | 知識庫/文檔 | 知識庫放我學習到的新知及閱讀筆記,甚至是向 AI 請教的領域知識;而文檔則是放符合個人需求的 SOP、疑難排解及個人系統地圖等 |
| Express 表達 | Resource 的產出狀態 | 個人文章庫 | 變成文章、作品的成果 |
資料庫各自怎麼用、怎麼輸入、怎麼讓 AI 讀得懂
| 庫 | 作用 | 怎麼輸入 | 必填欄位 / 讓 AI 讀得懂的設計 |
|---|---|---|---|
| 靈感收集箱 | 捕捉一閃而過的點子 | 手機捷徑/Telegram/隨手丟一句話 | 一句話(title)、建立時間、處置(status:待分類/已升級/封存) |
| 行動任務 | 要做、有完成定義的單一動作 | 從靈感升級/專案拆解 | 狀態(status)、所屬專案(relation)、分類(select)、截止日(date)、AI 摘要(text) |
| 專案 | 任務的集合、有截止 | 靈感升級/手動開 | 狀態、完成定義(text)、關聯任務(relation)、完成度(formula) |
| 知識/文檔 | 參考素材、萃取成產出 | 貼 URL/讀書筆記 | 類型(select)、來源 URL、狀態(收集→閱讀→產出)、相關領域(relation)、AI 摘要 |
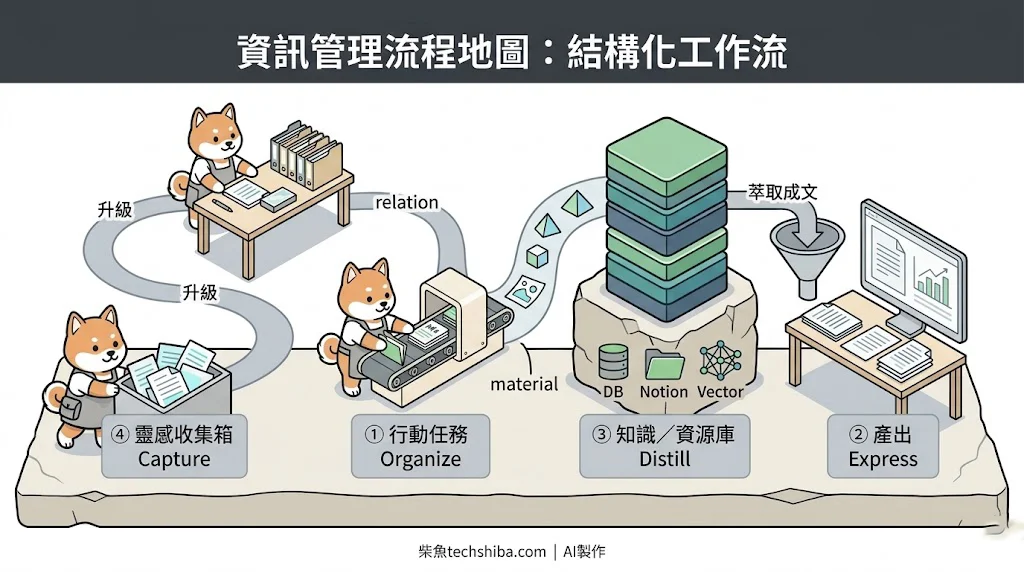
① 靈感收集箱(Capture)。 它的作用只有一個:當我腦袋閃過任何東西,直接零摩擦丟靈感。所以它的欄位少到只剩三個:內容、建立時間、status(待分類/已升級/封存)。輸入方式我刻意做到最低門檻:手機捷徑一鍵或丟一句話自動進庫。重點是不要在捕捉的當下逼自己分類,分類是後面 AI 的事。
② 行動任務+專案(Organize)。 這是「要被執行」的東西住的地方。我把專案和任務拆成兩張表,用 relation 綁起來:任務掛在專案底下,專案的「完成度」用 formula 自動算任務完成比例。這樣我不必手動更新進度,AI 也不必猜——它讀 formula 就知道專案跑到哪。任務的輸入幾乎都來自專案拆解,或是「靈感收集箱」的升級任務。
③ 知識/文檔(Distill)。 這裡放「要被參考」的資源:剪藏的文章、貼的 URL、讀書筆記或是 AI 問答及分析。最關鍵的設計是那個三段式 status:收集 → 閱讀 → 產出。它讓這個庫不是死的書籤堆,而是一條會推進的萃取線。AI 只要讀 status,就知道哪些是我正在學習的素材,哪些是我已經學會、可以拿來運用的。
④ 產出(Express)。 嚴格說它不是獨立一張表,而是接在知識庫「產出」狀態、再串到我的個人文章庫。一筆素材一旦被萃取成文章或 Threads,資訊就從「閱讀」推進到「產出」,而且知識和產出之間一定要設計關聯欄位,好追蹤來源。
另外分享資料庫收斂原則:每個庫的主屬性盡量 ≤ 12 個,超過就拆或移到頁面內文;**跨庫資料一律用 relation/rollup,絕不複製貼上,**一筆資訊只住一個地方,這是整套系統好維護的秘訣。
這篇真正的重點:怎麼請 AI 幫我充實資料庫
⭐ 前面講的都是骨架,這一段才是肉——資料庫建好之後,怎麼讓 AI 幫你把它養肥,而不是你一個人苦工填欄位。
先講一個前提,這也是為什麼前面我一直碎念「為 AI 設計 schema」:你能不能請 AI 充實資料庫,取決於你的欄位 AI 讀不讀得懂。 善用 select/status,AI 才能精準 filter、精準回填;每個庫留一個「AI 摘要」text 欄,讓 AI 自動填寫,也方便 AI 及時概覽檢索資料。
設計到位之後,有三種模式可以請 AI 協助充實資料庫,填充第二大腦:
模式一:單筆深化。
「這是我剛丟進知識庫的一篇文章(貼連結/內文)。幫我:① 判斷它該歸哪個『類型』;② 寫一段 80 字以內的『AI 摘要』;③ 建議它該關聯到哪個『相關領域』。直接給我可以填進欄位的值。」
因為欄位都是 select / relation / 短文字,AI 給的答案我複製貼上就能用,不必再翻譯。
模式二:批次補欄。 面對一堆舊資料(例如我早期亂丟、沒分類的幾十筆靈感),我用 Notion 的 AI 屬性/autofill 功能,整批補「分類」「摘要」。設定一次規則,由 Notion AI 一筆一筆填。這對「補齊歷史欠債」特別有用。
模式三:從輸入到產出。 知識庫裡某篇推進到「閱讀」狀態的素材,我會請 AI 直接提供我下一步動作或是創作產出:
「這篇文章我已經讀完。這段知識有甚麼適合我的地方運用方式,另外幫我萃取成 3 條 Threads 草稿及一段可以放進長文的論點。」
關鍵心法是:你不是「請 AI 寫作業」,你是「讓 AI 輔助你的工作流」。 收集 → 閱讀 → 產出,每一段交界 AI 都能接手,這就是「能跟 AI 對話的 schema」真正的價值,讓 AI 變成你的資料庫管理員。
我的實際運用
講一個我每天運用 Notion 資料庫的例子,你會更有感。
某天通勤時我冒出一個寫作點子,手機捷徑一句話丟進靈感收集箱(Capture)。當晚我請 AI 把它分類、判斷值不值得寫,值得的就一鍵升級成行動任務(Organize),自動掛到對應專案底下。寫的過程我需要素材,就去知識/資源庫(Distill)撈那些 status 已經是「閱讀」的文章,請 AI 萃取成論點。文章寫完發布,那筆素材推進到「產出」(Express),整圈收尾;而這條 idea 從捕捉到變成一篇文,全程沒有任何一筆資料是手動搬運,全部由自動化機制及 AI 輔助完成。
最直接的好處是我現在的日誌、週報是用腳本篩選我每日 Notion 資料庫痕跡,並以 AI 讀寫自動生初稿的。它掃過這週所有「已完成」的任務、推進到「產出」的素材,以前要花一個多小時回想「這週到底幹了什麼」,現在資料庫自己記得。
結論:我繞了一大圈才學會的事
那十幾個半路陣亡的資料庫,是我實實在在繳出去的學費。當時我一直以為問題出在模板不夠好、教學看得不夠多,換了一輪又一輪,照樣三個月就荒掉。後來才想通,真正缺的從來不是工具,而是我從沒先停下來問一句:「資訊在我這裡,到底是怎麼流動的?」
順序其實很簡單,先看懂運用,才談得上結構;先把結構設計成 AI 讀得懂,AI 才接得了手。這三步一旦對了,資料庫真的就夠用很久,而且會越用越順。
我不敢說這套系統有多完美,到現在我每隔一陣子還在改。但至少現在我的 Notion 就從一個只會堆東西的倉庫,變成一個好使用的第二大腦。
所以如果你也正準備重整你的 Notion,先別急著抄,拿張紙,把你自己需求及習慣寫下來,系統性思考後,我猜你會發現,你的需求不需要參考那些花裡胡哨的模板。
延伸閱讀(同系列):
- 回頭看這套系統的源頭觀點:AI 資料庫建好了,你的 AI 才真的好用
- 想先打好 AI 使用基礎:2026 生成式 AI 入門指南
- 接下來會寫:怎麼把資料庫結構寫成一份 AI 讀得懂的導覽文件(CLAUDE.md 的煉成)
外部延伸:Tiago Forte 的《打造第二大腦》(Building a Second Brain),書中提出的 CODE × PARA 框架,是這整套設計的理論底。
常見問題
- Notion 個人資料庫到底該建幾個?
- 不必為每個主題各開一個。依《打造第二大腦》CODE 流程,只要四個對的資料庫——靈感收集箱、行動任務(+專案)、知識/文檔、個人文章庫,用 relation 串起來,就勝過幾十個孤島資料庫。
- Notion 資料庫該依主題分類,還是依別的方式?
- 依「資訊在工作流的哪個階段」分類,而不是依主題。問三個問題:這筆資訊從哪進來、要被執行還是被參考、最後變成什麼產出,分別對應 CODE 的捕捉/組織/萃取/表達。
- 怎麼讓 AI 幫我充實 Notion 資料庫?
- 前提是把欄位設計成 AI 讀得懂——多用 select/status、每個庫留一個「AI 摘要」欄。接著用三種模式:單筆深化、用 Notion AI autofill 批次補欄、把「閱讀」狀態的素材直接請 AI 萃取成產出。
- CODE 和 PARA 有什麼關係?
- CODE 是 Tiago Forte 描述資訊生命週期的流程(捕捉→組織→萃取→表達),PARA 是分類法。本文把 CODE 階段對應到實際資料庫,其中組織階段用專案+行動任務兩張表,對應 PARA 的 Project。